Data is al heel wat jaartjes hip. Processen worden altijd een beetje als saai gezien.
Toch zijn ze onlosmakelijk met elkaar verbonden. Data is gewoon onderdeel van een proces.
Tenminste, zoals ik er naar kijk. Dus, hoe kijk ik er naar?
Doel is het laten presteren van processen; procesmanagement dus
In een eerdere post kon u al lezen dat ik procesmanagement opdeel in 3 niveaus (met daarboven eigenlijk nog het meer strategische ‘Waarom?’ niveau):
- De uitvoering van een proces voor een individuele zaak
- Besturing van alle lopende zaken in een bepaald proces
- Verbeteren van het procesontwerp voor een bepaald zaaktype
Wanneer ik organisaties help om al deze niveaus van procesmanagement in te richten, is belangrijk om te begrijpen wat je allemaal nodig hebt om een proces te laten presteren.
Zodat je niveau 3 niet zo vaak hoeft te doen.
Dat betekent dat we dan kijken naar diverse samenwerkende proces aspecten als:
- Wat is het werk dat moet gebeuren (de werkstroom)?
- Wat voor type mensen met welke capaciteiten zijn daar voor nodig?
- Welke hulpmiddelen zijn benodigd?
- Wat is de beste manier om dit proces te besturen (bijv. taakgericht of doelgericht)?
Er zijn meer aspecten, maar degene waar ik in dit verhaaltje op in wil gaan is Data.
Want u heeft waarschijnlijk al diverse artikelen gelezen waarin u las dat data ‘het nieuwe goud ‘ is. Ook herinnert u zich vast de gloriedagen van ‘Big Data’ of leest u weer een quote dat we nu meer data in een minuut produceren dan onze grootouders in een heel millennium. En laten we dataverslindende AI gadgets niet vergeten.
Super cool, maar wat heeft het te maken met processen inrichten, besturen en verbeteren?
Veel. Want in bijna alle processen speelt data (of zou het beter zijn om het informatie te noemen?) een grote rol. Maar data in het algemeen is ook maar data, dus daarom maak ik altijd onderscheid, net als de cirkeltjes uit een eerder artikel, in het gebruik van data op verschillende niveaus van procesmanagement:
- Data om een proces voor een individuele zaak uit te voeren
- Data om alle zaken die momenteel lopen te kunnen besturen
- Data om het proces(ontwerp) te kunnen verbeteren
- Data als verbinding tussen verschillende processen
Om dit uit te leggen, gebruik ik weer m’n ‘Bezorgen pizza’ proces:

Data die nodig is om het proces uit te voeren
In het proces ‘Bezorgen pizza’, is het gewenste procesresultaat een bezorgde pizza. Maar, het start allemaal met een klant die de wens heeft om een pizza te laten bezorgen. Om alle tussenliggende handelingen uit te kunnen voeren, is informatie benodigd.
Om de pizza te maken is informatie nodig als:
- Welke pizza wil de klant?
- Welk formaat?
- Welke extra toppings zijn er besteld?
Om de pizza te kunnen bezorgen, is informatie nodig als:
- Bezorgadres
- Gewenste bezorgtijd
- Telefoonnummer
Dit maakt ook duidelijk dat stappen die je vaak in het begin van een proces ziet, als ‘Vastleggen bestelling’ alleen maar nodig zijn om bovenstaande data te verkrijgen. Het vastleggen van deze data voegt geen waarde toe aan het maken of bezorgen van de pizza. Het voorziet het proces enkel van informatie. Maar wel nodig natuurlijk.
En daarom moet er, zeker in de huidige ‘multi-channel-tijd’, tijdens procesontwerp nagedacht worden over hoe de data in het proces belandt.
- Telefoon
- Bestelwebsite
- Bestel app
Omdat de Customer Journey ook een hip ding is, is het belangrijk dat het de klant niet heel erg moeilijk wordt gemaakt om u van deze data te voorzien.
Bovenstaande is dus data voor een individuele case. Hopelijk krijgt deze pizzeria meer dan 1 bestelling per dag. En daarmee kom ik op het volgende niveau van data.
Data om alle zaken in een proces te managen
Veronderstel dat op een bepaald moment in de avond zich 8 bestellingen in het proces bevinden. Medewerkers werken aan de individuele bestellingen, maar tenminste één iemand zal de rol van procesmanager moeten spelen om ‘alle zaken in de gaten te houden’. Dat betekent dat er informatie nodig is over hoe de zaken er voor staan.
Voor mij zou dat betekenen dat je de status van alle zaken in het proces weet en dat duidelijk is of ‘de belofte wordt waargemaakt’
En die belofte kan, vanzelfsprekend, van proces tot proces verschillen. In een vorige post hield ik het simpel door alleen de bezorgtijd (binnen 50 minuten) in ogenschouw te nemen. Omdat waar te kunnen maken is dus voor elke bestelling inzicht in deze belofte nodig:

Dit is traditioneel proces monitoring, maar voor mij nog steeds essentieel in ‘doen wat je belooft’. Dit is wat ik ‘op het veld’ noem. Want op dit moment kan nog ingegrepen worden in zaken waar de belofte mogelijk niet waar gemaakt kan worden.
Wanneer u nadenkt over de inrichting van zaakmonitoring, kunt u ook nadenken over in hoeverre u deze gegevens beschikbaar wilt stellen aan een klant. Het schijnt ‘the age of the customer’ te zijn, dus wilt u hem/haar informeren over de voortgang van de zaak?
Dit monitoring niveau van procesdata gaat om ‘doen wat je belooft voor de individuele klant’. In dit geval pizza’s op tijd bezorgen.
Nadat je meerdere individuele klanten hebt geholpen, wordt waarschijnlijk ook duidelijk hoe goed het proces in het algemeen is ingericht.
Tenminste, als u daar de juiste data voor verzamelt. En daarmee zijn we op niveau 3 van data in procesmanagement beland.
Data om processen te verbeteren
Dit derde niveau van data gaat over traditioneel procesverbeteren. Presteert het proces zoals we het ooit hebben bedacht, of heeft het een opknapbeurt nodig? Het is de klassieke Village People hit ‘PDCA’.
Maar om te weten of het ‘beter’ moet, zul je eerst ‘goed’ moeten definiëren.
In mijn simpele pizza voorbeeld is dat ‘Bezorgd binnen 50 minuten’. Maar in het echt gelden vast meer doelen als:
- Lekker (hoewel smaken verschillen)
- Warm (> 78 graden)
Of interne doelen als:
- Winstmarge op pizza > 34%
En dan hebben we het nog niet eens gehad over doelen opgelegd door andere belanghebbenden als wetgever of controlerende instanties als de NVWA.
Om te kunnen bepalen hoe goed het proces het doet (of eigenlijk ‘heeft gedaan’), is data over procesprestaties benodigd. Dat kan natuurlijk verzameld worden door te meten, spreadsheets bij te houden of misschien zelfs met mooie management informatie dashboards in een BPM tool.
En dat maakt mij verder ook niet uit, zolang de data je maar iets zinvols vertelt over de prestaties van je proces. Sinds een aantal jaar zou ook Process Mining hierbij een toepasbaar hulpmiddel kunnen zijn.
Process Mining is technologie dat data gebruikt van de systemen die worden toegepast om processen uit te voeren. Vervolgens wordt deze data (die over de verschillende afgehandelde zaken gaat) omgezet naar een ‘procesgeoriënteerde kijk’, om op die manier iets over het proces te weten te komen.
De meeste process mining tools hebben diverse mogelijkheden om deze data te representeren. Een basisplaatje is vaak een figuur van de werkstroom met daaraan gekoppeld de gemiddelde bewerkingstijd van activiteiten en de gemiddelde wachttijd tussen de activiteiten (weergegeven op verbindingen).

Na een beetje rekenen (wat de process mining tool vanzelfsprekend ook voor u kan doen) is de conclusie dat de gemiddelde doorlooptijd 50 minuten en 33 seconden bedraagt.
Maar, wat heb je nou aan gemiddeldes? Ik heb op school niet zo heel goed opgelet bij statistiek, maar niet zo heel veel, geloof ik. Daarom hebben de meeste process mining tools ook de mogelijkheid om doorlooptijden, wachttijden etc. anders te tonen.
Bijvoorbeeld de minimale en maximale waarde. Dit geeft al een kleine indicatie van de variantie.
Het volgende plaatje laat de minimum en maximum bewerkingstijd van activiteiten en de minimum en maximum wachttijd op verbindingen zien.
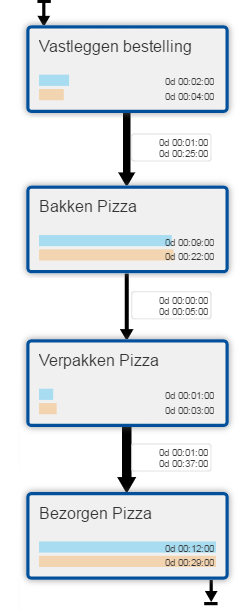
Even de TI 30 stat er bij pakken en u ziet dat de snelste bestelling in 38 minuten werd bezorgd en dat de langzaamste er 1 uur en 25 minuten over deed. Is dat erg? Waarschijnlijk niet zo leuk voor de klant die 35 minuten langer dan beloofd moest wachten. Maar maakt dat het direct noodzakelijk om te sleutelen aan het procesontwerp?
Meer inzicht daarin verkrijg je door alle doorlooptijden in een grafiek te laten zien (ook standaard functionaliteit van een fatsoenlijke process mining tool).
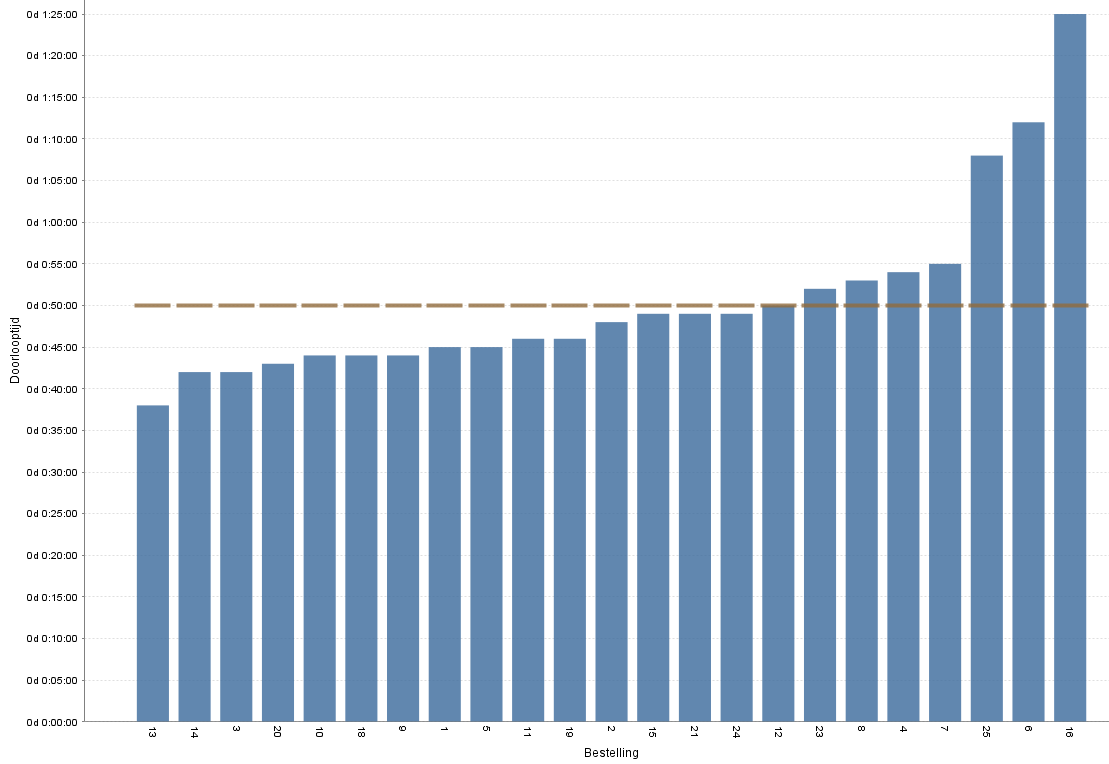
Nu is zichtbaar dat 7 van de 23 bestellingen een langere doorlooptijd dan het doel van 50 minuten hadden. Of dat goed of slecht is, mag elke organisatie zelf bepalen. Maar voor de 7 klanten die de pizza te laat kregen, is er niks meer aan te doen. We kijken immers naar gegevens uit het verleden. Vandaar dat ik traditioneel procesverbeteren ook wel ‘kleedkamerpraat’ noem.
Een ander ding om te beseffen, is dat al deze proces prestatie informatie slechts symptomen laten zien. Om het proces te verbeteren, zul je echter op zoek moeten naar de oorzaken.
Toch kan process mining al wel wat indicaties geven over waar te zoeken naar de oorzaken van bijvoorbeeld een lange doorlooptijd. Zo was te zien dat bestellingen een behoorlijke tijd spenderen aan wachten. Bijvoorbeeld tussen de stappen ‘Verpakken pizza’ en ‘Bezorgen pizza’.
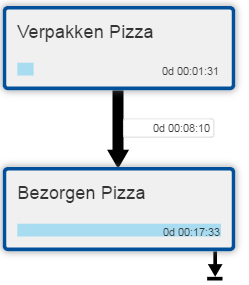
Nog steeds een symptoom, maar dit zou kunnen leiden tot een onderzoek waarin duidelijk wordt waarom bestellingen gemiddeld 8 minuten wachten voordat ze worden opgepakt voor bezorging.
Om nog meer inzicht te krijgen in verstoringen van ‘de flow’, bieden process mining tools ook de mogelijkheid om de stroom van gevallen in een soort van filmpje te tonen. Wat er in feite gebeurt is dat het logbestand op een procesgeoriënteerde manier wordt nagespeeld. Hierdoor worden bottlenecks nog visueler (dit is overigens een statisch plaatje) weergegeven.

En dan ‘nog even’ een oplossing bedenken en implementeren 😉
En dat was niveau 3 van data; procesverbetering. Niveau 2 ging over de dagelijkse procesgang van zaken (in dit geval pizzabestellingen) en op niveau 1 zagen we de data benodigd voor een individuele bestelling.
Wanneer ik organisaties help met het knutselen aan processen, benoem ik ook altijd nog een ander type data; data die stroomt tussen processen.
Data die stroomt tussen processen
De meeste organisaties hebben meer dan één proces. We weten al dat de pizzeria een proces heeft voor ‘Bezorgen pizza’, maar er zullen ook processen zijn voor ‘Afhalen pizza’ en misschien ook wel voor ‘Eten in het restaurant’. Daarnaast verwacht ik processen om de voorraad (van deeg, tomaten, saus, dozen, etc) op het gewenste niveau te houden.
En tussen al deze processen bestaan ook datastromen. Want als je 50 pizza’s per dag verkoopt, heeft dat gevolgen voor de voorraad. Dus het proces ‘Bezorgen pizza’ genereert data (50 pizza’s gemaakt), wat weer gevolgen heeft voor data in andere processen (de huidige voorraad van goederen).
‘Bezorgen pizza’ en ‘ Voorraad op gewenste niveau houden’ zijn dus processen met een relatie. Die relatie is niet de stroom van een zaak, maar gebaseerd op de data die in die processen gegenereerd wordt:

Processen sturen dus data naar ‘databases’ met informatie en ander processen maken weer gebruik van die data. Hier zijn vele voorbeelden van te bedenken. Bijvoorbeeld klantinformatie die in het ene proces wordt geactualiseerd en in het andere proces weer nodig is.
Dit maakt weer mooi duidelijk dat ‘de processelarij’ heel veel andere vakgebieden raakt zoals informatiemanagement en data-security.
En dat komt omdat dit niveau 4 van data zich meer op een organisatie- of procesarchitectuurniveau bevindt. Hiermee wordt ook duidelijk dat de prestatie van het ene proces invloed kan hebben op een ander proces.
Heel wat data, dus. Een belangrijk aspect van presterende processen, denk ik. Maar niet het enige. Vandaar ook dat ik processen altijd een goed uitgangspunt vind om naar organisaties te kijken.
Een proces is een verzameling van allerlei samenwerkende factoren. Niet alleen blokjes en pijltjes (en als u van BPMN houdt, ook wat cirkeltjes). Daarom blijf ik procesmanagement zo interessant vinden.
Gebruik uw data slim en happy processing!